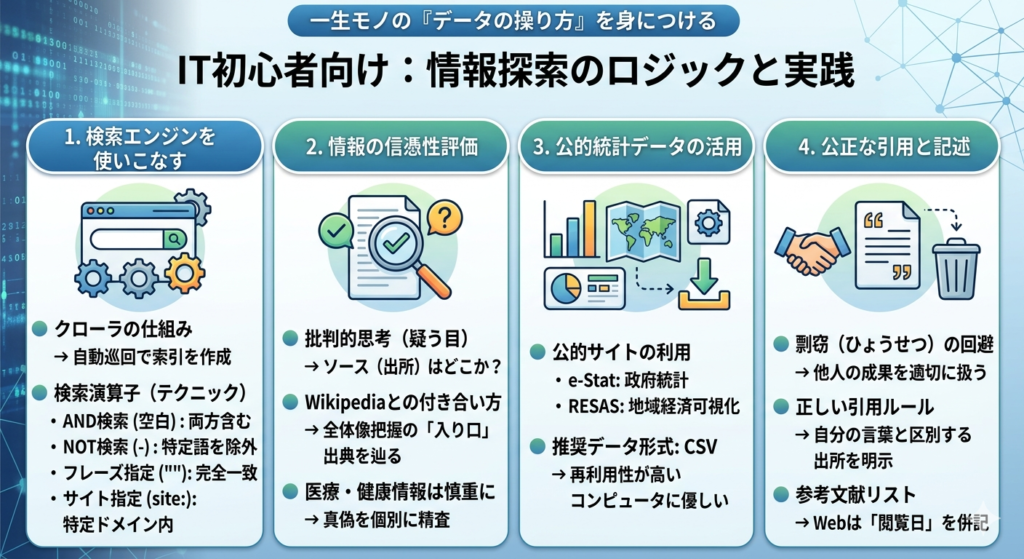
IT業界への転職やステップアップを目指す際、プログラミングやツールの使い方と同じくらい重要になるのが「情報を正しく探し、正しく扱う力」です。
エンジニアの仕事は、実は「検索」の連続です。エラーの解決策を探す、新しい技術のドキュメントを読む、信頼できる統計データを引用して提案書を書く……。このとき、情報の真偽を見極められなかったり、他人のコードや文章を不適切に扱ったりすると、思わぬトラブルや信頼の喪失に繋がります。
本稿では、IT初心者の方が「情報収集のプロ」になり、学術的・専門的なレベルで通用するアウトプットを出せるようになるための技術体系を徹底的に解説します。
第1章:検索エンジンの「裏側」を理解し、探索をハックする

私たちが毎日使うGoogleなどの検索エンジンには、明確な「論理(ロジック)」があります。これを知っているだけで、検索のスピードは劇的に上がります。
1-1. アルゴリズム:なぜそのページが一番上に来るのか
検索エンジンは、「クローラ」と呼ばれる自動巡回ソフトが世界中のWebサイトを回り、巨大な索引(インデックス)を作っています。
- Googleの評価基準: 簡単に言えば「多くの人からリンクされている(紹介されている)ページは価値が高い」という論理が基本です。
- AIとの統合: 最近ではBingのようにAIが回答を生成するタイプも増えていますが、AIも元となる情報をどこかから探してきているに過ぎません。
1-2. エンジニア必須の「検索演算子」テクニック
狙った情報を最短で見つけるために、以下の記号を使いこなしましょう。
- AND検索(空白): 「Python 入門」のように語句を並べる基本。
- OR検索(OR): 「Windows OR Mac」でどちらかを含むページを探す。
- NOT検索(-): 「Java -JavaScript」のように、特定の語を除外する。ノイズを消すのに最適です。
- フレーズ指定(” “): 「”初心者がエンジニアになる方法”」と囲むと、その語順通りの完全一致で探せます。
- ドメイン指定(site:): 「site:go.jp」を付ければ、政府の公式サイト内だけを検索できます。情報の信頼性を確保する最強の手段です。
第2章:情報の「信憑性」を見極める批判的思考
Webにある情報がすべて正しいとは限りません。エンジニアは常に「この情報のソース(出所)はどこか?」と疑う目を持つ必要があります。
2-1. メディアの特性を知る
「ネットは嘘ばかり、本は正しい」というのは極端です。
- Webサイト: 最新情報は早いが、広告収入のために「釣りタイトル」や不正確な内容でアクセスを稼ごうとするサイトも多い。
- 書籍: 編集者のチェックが入っているため信頼性は高めだが、出版された瞬間に「情報が古くなっている」リスクがある(特にIT分野)。
2-2. Wikipediaとの「正しい付き合い方」
Wikipediaは非常に便利ですが、誰もが編集できるため、それを「最終的な根拠」としてレポートや仕事の資料に書くのはNGです。
- エンジニア流の使い方: 全体像をざっくり把握するために使い、記述の最後にある「出典(リンク)」を辿って、一次資料(公式文書や論文)を確認するための「入り口」として活用します。
第3章:専門情報へアクセスする「深い」ルート
一般の検索では辿り着けない、価値の高い情報源を知っておくのがプロへの近道です。
3-1. 電子ジャーナルとリポジトリ
大学や研究機関が公開している「機関リポジトリ」には、専門家の研究成果が無料で公開されていることがあります。また、Google Scholarなどを使えば、学術的な論文を効率よく探せます。
3-2. デジタルアーカイブの活用
過去の一次資料(古い文献や公文書)をデジタル化したアーカイブも強力です。例えば「ジャパンサーチ」などの横断検索ツールを使えば、ネットに転がっている二次情報ではなく、本物のデータに基づいた説得力のある資料が作れます。
第4章:客観的な「数字」で語るための公的統計
主観(〜だと思う)ではなく、客観的な事実(データ)で語るのがエンジニアの流儀です。
4-1. 公的統計サイトを使い倒す
- e-Stat(政府統計の総合窓口): 日本のあらゆる統計データ(人口、経済、労働など)が集約されています。
- RESAS(地域経済分析システム): 地域の産業や人の流れを「地図」で可視化できるツールです。
4-2. CSV形式:コンピュータに優しい形式を選ぼう
統計データをダウンロードする際、PDF、Excel、CSVなどの形式があります。
- エンジニアの推奨: 圧倒的にCSV形式です。余計な装飾がなく、プログラムや分析ツールでそのまま扱えるため、再利用性が最も高い形式です。
第5章:図書館を「巨大なデータベース」としてハックする
Webにない情報は、今でも膨大に「紙の形」で眠っています。
5-1. 日本十進分類法(NDC)というインデックス
図書館の本の背表紙にある数字。これはNDC(日本十進分類法)という論理的な住所です。
- 000: コンピュータ・情報
- 300: 社会科学(ビジネス・経済)
- 400: 自然科学(数学・技術)この番号のエリアに行けば、自分が探しているテーマに関連する本が芋づる式に見つかります。図書館は「物理的な検索エンジン」なのです。
5-2. 図書館員(司書)は「最強の検索エンジニア」
もし探しものが見つからないなら、「レファレンスサービス」を使いましょう。司書さんは情報のプロです。あなたの代わりに、適切な資料やデータベースを提示してくれる、まさに人間版の高度な検索エンジンです。
第6章:情報の「倫理」:知的財産を守る書き方の作法
情報をまとめる際、絶対にやってはいけないのが「剽窃(ひょうせつ)」、つまり他人の成果を自分のものとして出すことです。
6-1. 引用のルールを死守する
他人の文章やコードを使うときは、以下のルールを必ず守ります。
- 区別: 「 」で囲むなど、自分の言葉と他人の言葉をはっきり分ける。
- 出所の明示: 誰の、どの本・サイトから持ってきたかを書く。
- 必然性: 自分の意見を補強するために、どうしても必要な分だけを引用する。
6-2. 参考文献リストの書き方
レポートや記事の最後に、参考にした文献を並べます。
- Webサイトの場合: URLだけでなく、「閲覧日」を必ず書きましょう。Webサイトは消えたり変わったりするため、「いつ確認した情報か」が非常に重要です。
6-3. 捏造・改竄の禁止
存在しないデータを作ったり(捏造)、都合のいいように書き換えたり(改竄)するのは、エンジニアとしてのキャリアを終わらせる行為です。正しいデータを正しく提示することが、あなたの信頼を築きます。
第7章:論理的なアウトプットのための文体
専門的な文書では、信頼感を与えるために書き方も工夫します。
- 常体(だ・である調)の使用: 個人的な感想ではなく、客観的な事実を述べるのに適しています。
- 感情を排する: 「〜で感動した」ではなく、「〜という結果が得られた」という、誰が読んでも同じ意味に捉えられる表現を心がけましょう。
結論:自律した「情報の制御者」になろう

情報が増え続ける現代において、情報をただ受け取るだけの「消費者」でいるのは危険です。
検索技術を磨き、情報の真偽を多角的に検証し、正しいルールで引用して自分の論理を組み立てる。この「情報の主体的制御能力」こそが、IT業界で長く活躍するための真の基礎体力となります。
あなたが今日検索する一つのキーワード。その背後にある論理を意識し、確かな情報源に辿り着く努力を惜しまないでください。その積み重ねが、あなたを「デキるエンジニア」へと変えていくはずです。
第8章:【付録】IT初心者が明日から使える「リサーチ・チェックリスト」
- 検索演算子を使ってみたか?:
-やsite:を活用してノイズを消しましょう。 - 一次ソースを確認したか?: Wikipediaやまとめサイトの裏にある、公式文書や統計を確認しましょう。
- 引用の区別はついているか?: 自分の言葉と他人の言葉が混ざっていないか、再確認しましょう。
- CSVデータを探してみたか?: PDFだけでなく、加工しやすいデータ形式を探す癖をつけましょう。
一歩踏み込んだリサーチが、あなたのアウトプットの質を劇的に変えます。